Technical debt in Firefox and Chromium
ALI ALMOSSAWI
Previously on...
A couple of months ago, I posted an article titled How maintainable is the Firefox codebase, which discussed how an important quality attribute, namely, maintainability, could be quantified. It looked at how Firefox was doing with respect to those measures and suggested some preliminary findings. The aim of this second, much shorter, article is to provide better context by comparing Firefox to another popular and complex software system. The upcoming third and final article will focus on the propensity of various modules for defects.
The original article has been slightly modified in two ways since it was first posted. The first is that .jsm files were added to the analysis, thanks to a few readers who noticed that they were missing. The second is that unit tests have been excluded from the analysis. The results have not changed much, since most of those unit tests were already being thrown out during the analysis. Nevertheless, certain bumps, such as those around v3 for example, are now more apparent.
Most of the material herein is based on a talk that I recently gave at Links 2013 titled ‘Measuring quality in a complex software system’, the slides for which may be found here.
1 Why is technical debt important?
Some things tend to degrade with time. Within the context of software, degrading means that a system deviates in two specific ways: that it no longer functions as well and that it no longer satisfies its quality attributes. Quality attributes are those cross-cutting requirements such as maintainability and reliability, which one may argue are more important for a system's success than functional requirements.
The buildup of harmful elements that lead to degradation may be said to be inevitable in software for a number of reasons, primary of which is the inherent complexity of software. To paraphrase Fred Brooks, this inherent complexity is due to the fact that no two components in software are the same1, which is in contrast to the physical disciplines where there is such a thing as matter and where components have physical attributes that are unequivocally apparent and constraining. Other factors that contribute to the buildup of these harmful elements include changes in team dynamics, business pressures that lead to tight deadlines, industry shifts and so on.
A term that is sometimes used to describe a subset of these harmful elements is technical debt. It is a fitting metaphor, as it indicates that a software engineering malpractice here or a concession with respect to coding standards there can incur a debt that one must then pay off in the form of time, effort or defects. In fact, it is typical for teams working on large projects to pay off this debt every so often in the form of a formal exercise known as a refactoring effort.
To demonstrate how seriously technical debt can impact complexity, and hence quality, here is an example due to my colleague Dan Sturtevant2. Imagine we have a simple system, made up of 12 components, which is to say, 12 files. If we model that system using an adjacency matrix and wherever there is one or more dependencies between two components, we mark it with a dot, we end up with a matrix such as the one in diagram 1 that has a density of 47. If we then find the transitive closure for that matrix, which means capturing not only direct dependencies, but indirect ones as well, we end up with a matrix that has a density of 81.
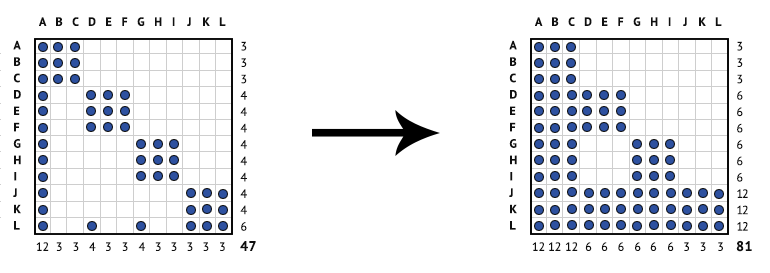
Diagram 1: The density of a simple system's direct (left) and indirect (right) dependencies.
Now, if we add just two dependencies between two sets of files, marked in red, in a way that breaks the design principle of modularity, and then find the transitive closure again, we end up with a matrix that has a density of 144. In other words, every component in the system can now potentially impact every other component were it be modified. By making only two changes, we have significantly increased the complexity of our system.
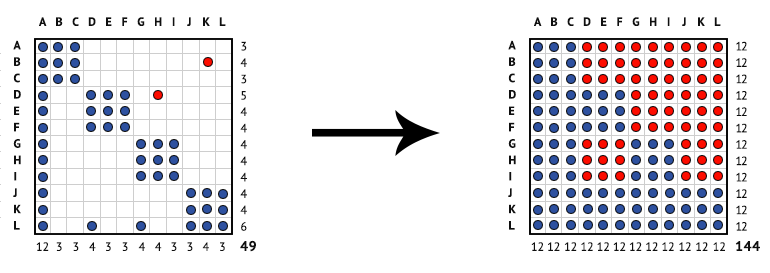
Diagram 2: The density of a simple system's direct and indirect dependencies after adding two new dependencies to it.
1 Frederick P. Brooks Jr., The Mythical Man-Month, 1995.
2 http://sdm.mit.edu/news/news_articles/webinar_050613/sturtevant_050613.pdf
2 Five measures of technical debt
To quantify technical debt, we use five measures that have been shown in various studies to be strong predictors of quality. The details of each metric have been previously discussed, though here is a quick rundown of them.
- Lines of code, which is a common measure of system size.
- Cyclomatic complexity, which is a measure of the internal complexity of components, or more specifically, the number of independent paths of execution within a component.
- Direct dependencies, which is a measure of the density of dependencies between components.
- Propagation cost, which is a measure of the density of direct and indirect dependencies between components. Propagation cost gives a sense of the number of components that a particular component could potentially impact were it to be modified.
- Core size, which is a measure of the proportion of highly interconnected components.
3 Our armory of tools
In order to capture those metrics, we use a simple armory of tools.
- Static analysis. A technique that allows one to analyze a codebase without having to execute it. Some use it to find defects; we use it here to generate lines of code, cyclomatic complexity and a map of inter-component dependencies.
- Network manipulation. Since we model our systems using matrices during analysis, a network manipulation tool allows us to transform those matrices and generate metrics such as direct dependencies, propagation cost and core size from them.
- Design Structure Matrix (DSM). In engineering disciplines, an adjacency matrix may be referred to as a DSM. A DSM proves useful not only for analysis, but also as a visualization tool, since it allows one to see various patterns of structural complexity within a system or module.
Here is an example of two DSMs for a system made up of 16,551 components. On the left is a DSM showing direct dependencies and on the right is one showing both direct and indirect dependencies. Not only are clusters in the latter matrix much more vivid compared to the former, but we also see that new clusters have emerged. The squares along the diagonals are modules; their intensity and size are an indication of a module's density of internal dependencies and size, respectively. Vertical lines indicate files that have a high fan-in, i.e. that have a lot of call-ins, and horizontal lines indicate files that have a high fan-out, i.e. that have a lot of call-outs.

Diagram 3: Direct dependencies (left) and indirect dependencies (right) for Firefox 16.
4 Gathering the Chromium data
The Chromium source-code can be accessed in one of several ways. In order to check out the source for specific releases, we use the gclient command-line tool. For the set of major releases, we use the major.minor.build.path strings from the Chrome release history page. There is a tool called OmahaProxy that allows one to translate Chrome revisions to SVN revisions should one wish to check out the source-code by revision. One can configure gclient to exclude certain files, such as WebKit Layout Tests for example, as described here. We check out the entire release, and then prior to analysis, use a bash script to remove unit tests, which make up a significant portion of the codebase.
Processing the Chromium data took on average an order of magnitude longer than Firefox, i.e. about 20 or so hours per release compared to two or so hours with Firefox. The result of that tedious process is the following dataset. For simplicity, Chromium releases are referred to using their major release number. For the full release string, please refer to the dataset. The dataset consists of 23 versions of Firefox—v1 to v20, and 23 versions of Chromium—v1 to v22. Due to machine limitations, I was unable to go beyond v22, for now. Newer versions, particularly v28, would be useful to include within the fold of this analysis because of the introduction of the Blink engine, which has reportedly resulted in the removal of several million lines of code.
5 How do Firefox and Chromium fare
As shown in tables 1 and 2 below, both Firefox and Chromium are fairly complex systems, making them worthy of analysis. Firefox has around 2.9 million lines of code on average per release and Chromium has around 4.8 million lines of code on average per release.
| Mean | Median | Stdev | Min | Max | |
| loc | 2,885,799 | 2,686,348 | 595,408 | 2,066,655 | 4,012,434 |
| files | 13,266 | 11,907 | 2,844 | 9,478 | 18,460 |
Table 1: Descriptive statistics for the set of Firefox releases (n=23)
| Mean | Median | Stdev | Min | Max | |
| loc | 4,767,974 | 5,157,958 | 1,951,894 | 896,204 | 7,331,584 |
| files | 29,020 | 31,132 | 12,349 | 5,009 | 46,620 |
Table 2: Descriptive statistics for the set of Chromium releases (n=23)
With lines of code, we see that Chromium is growing at a higher rate of 7.31% compared to Firefox's 2.66%. Chromium begins with a smaller codebase up until v4 when it jumps by 52.61% to 3.26 million lines of code. In Firefox, the largest increase in lines of code occurs in v4 when it goes up by 15.63% to 2.64 million lines of code. Recall that we are only looking at executable lines of code here and are excluding unit tests.
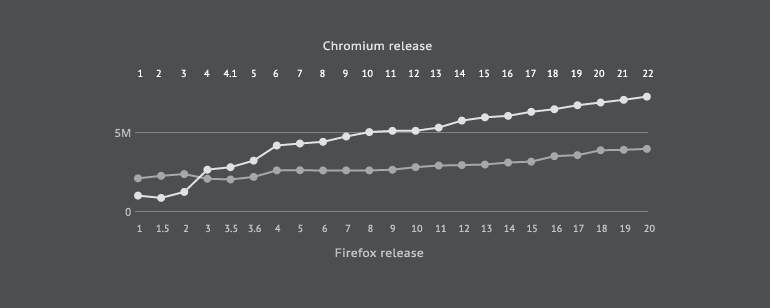
Chart 1: A comparison of lines of code.
With cyclomatic complexity, we see that Chromium has a consistently lower cyclomatic complexity per kloc compared to Firefox, seeing as it is 122.26 on average compared to 188.37 on average in Firefox. In both systems, the general trend is a downward one. In Firefox, we see an increase in cyclomatic complexity between versions 1 and 3.5, following which the downward trend begins. In Chromium, we see a noticeable increase in v2 and then a second noticeable increase in v6. What the result tells us is that the files in Chromium are internally less complex than in Firefox, meaning that the coding constructs in them result in fewer independent paths.
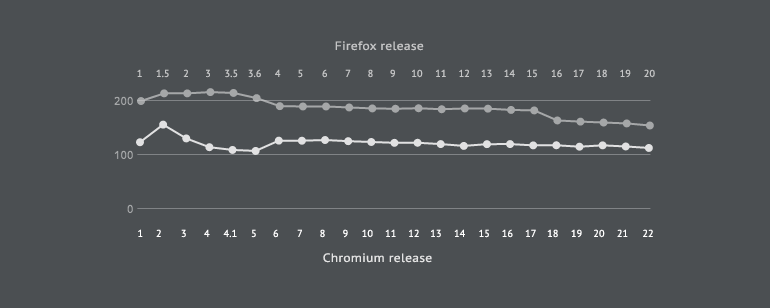
Chart 2: A comparison of cyclomatic complexity.
With direct dependencies, we see that both Chromium and Firefox are following a downward trend. Chromium begins with a much higher density of direct dependencies, the highest being 18.20 per 10,000 file pairs in v2. Direct dependencies in Chromium drop in v4 by 116.21%, following which they decrease at an average rate of 5.08%. Firefox's density of direct dependencies indicates a decreasing trend at an average rate of 2.60%, with the only discernible increase occurring between versions 3 and 4. A change to a randomly selected file in Chromium can directly impact 14 files, whereas a change to a randomly selected file in Firefox can directly impact 10 files.
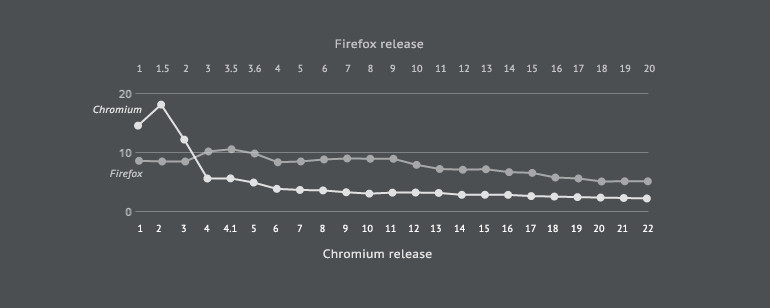
Chart 3: A comparison of direct dependencies per 10,000 file pairs.
With propagation cost, we see that Chromium is consistently more complex than Firefox, with an average propagation cost of 29.88% compared to Firefox's 17.45%. With Firefox, propagation starts at around 4.02% in v1 and increases steadily at a rate of 56.86% until v5, after which it stabilizes at 20.53% and its growth rate drops to 2.09%. Recall that v5 is when the Rapid Release Cycle began. With Chromium, we see a significant growth in propagation cost between v2 and v4 and then a negligible one thereafter. What propagation cost tells us, in practical terms, is that a change to a randomly selected file in Firefox has the potential to impact 2,308 files, on average. In Chromium, a change to a randomly selected file has the potential to impact around 8,562 files, on average.
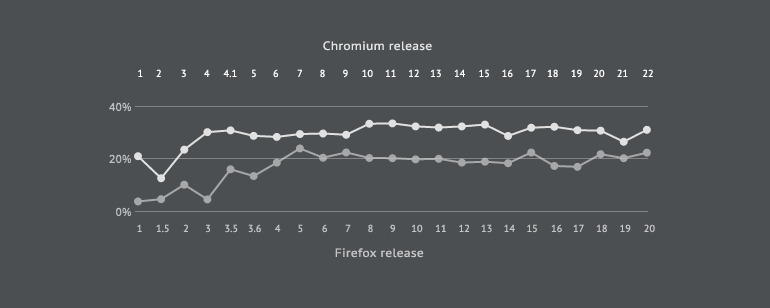
Chart 4: A comparison of propagation cost.
Similarly, with core size, Chromium is consistently more complex than Firefox. The average core size in Chromium is 33.22% compared to Firefox's 21.39%. Hence, the number of highly interconnected files in Chromium is noticeably higher than that of Firefox, which is to say that it is more likely for a new or modified file in Chromium to increase the system's complexity than in Firefox.
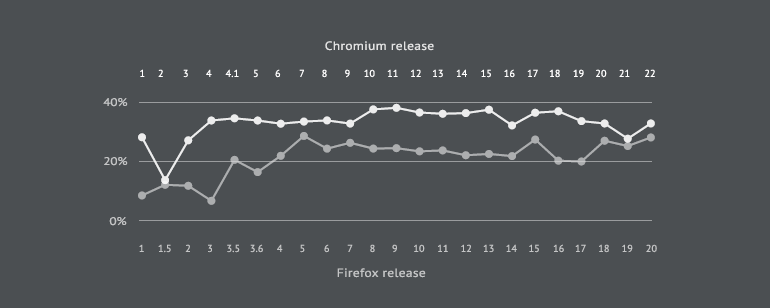
Chart 5: A comparison of core size.
6 Take-away
The take-away here is that Chromium and Firefox are complex in different ways. Whereas Chromium has a lower cyclomatic complexity and a lower density of direct dependencies, Firefox has a noticeably lower propagation cost and noticeably lower core size. Moreover, Firefox is growing at a lower rate and for a longer period of time—nine years compared to five years. Also, because Firefox is smaller in size, despite its higher density of direct dependencies, making a change to a file in practice can impact fewer files—10 compared to 14. All metrics being equal, an impartial observer may conclude that Firefox fares better than Chromium with respect to technical debt.
7 Highly interconnected files in Firefox and Chromium: a poster
The following static visualization compares the proportion of highly interconnected files in both systems, drawing inspiration from a story from Greek mythology. The story is about someone called Icarus whose father created wings for, sewing them with wax. He was told not to get too close to the sun or else the wax would melt and he would fall into the ocean and drown. Of course, he did just that and tragically met his demise. It seemed fitting to use that as a metaphor and perhaps say the same about highly interconnected files: the more of them a system has, the more difficult it becomes for it to remain in flight due to increased complexity and a higher likelihood of defects3. Below are some sketches for the visualization followed by the final piece.
3 Refer to the original article for relevant citations.

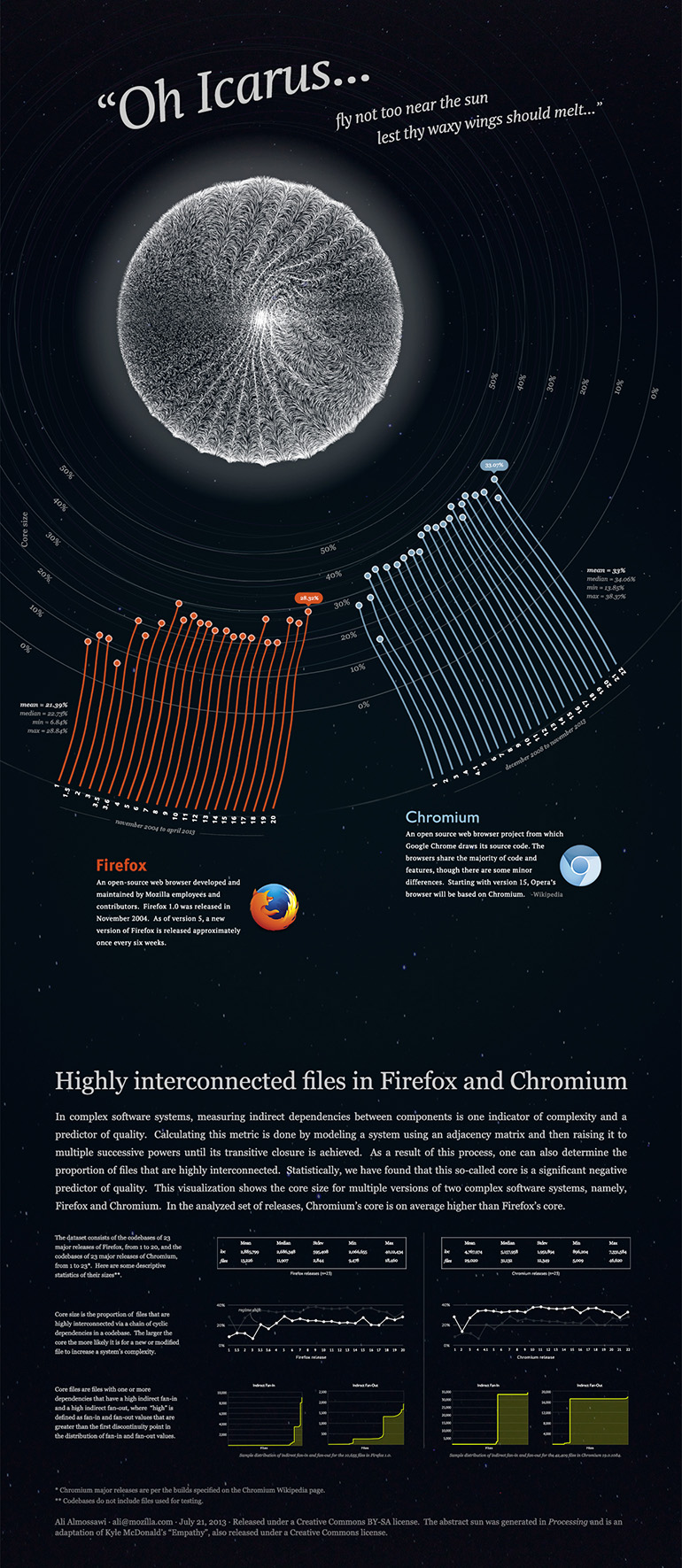
Diagram 4: Highly interconnected files in Firefox and Chromium visualization.
The hi-res version of the visualization may be downloaded from here and is also available on Visually.
{kind=link}
8 Next steps
An upcoming article will focus on defects, specifically, modules that show the highest propensity for regressions.
9 Acknowledgements
Thanks to Fabien Tassin for promptly responding to my Chromium inquiries.
← Read the first article in this series: How maintainable is the Firefox codebase?
Once again, here are the slides from my recent talk. This work is being shared under a Creative Commons license (CC BY-NC). To share your thoughts, feel free to chat with me on Twitter. You may download the data from here, here and here.
ali@mozilla.com · August 1, 2013