How maintainable is the Firefox codebase?
ALI ALMOSSAWI
Abstract
This work explores a particular facet of quality in Firefox, namely, maintainability. By appealing to the explanatory powers of five practical measures of architectural complexity, and with the aid of static analysis and network manipulation tools, we arrive at some preliminary findings. We find that 21% of files in Firefox are highly interconnected, a value that went up significantly following version 3.0. We find that making any change to a randomly selected file can, on average, directly impact 10 files and indirectly impact over 2,300 files. We see that files' internal complexity is on average going down. Their external complexity as measured by direct dependencies is also going down, whereas their external complexity as measured by propagation cost has remained steady. With respect to process, we find that the switch to the rapid release cycle from version 5.0 onwards had a positive impact on quality. Though the analysis reveals no imminently alarming red flags when it comes to maintainability, it does shine light on a number of issues that would be worth investigating. An upcoming article will take a closer look at how Firefox's architectural measures of complexity compare to those of other open-source projects.
1 Intro
The question that motivated this inquiry was: “How healthy is the Firefox codebase”, which suggests that the fundamental facet of interest in the system at hand is its quality. The goal of this work was two-fold:
- Answer said question.
- Build an interactive Web-based exploratory tool that makes the data accessible and allows people to draw their own conclusions.
2 Defining quality
As actively developed software ages, it tends to grow in size and can accumulate what is known as technical debt, wherein tiny deviations from a good process, shortcuts here and there and less than optimal code changes build up into debt that the team is then forced to pay off in the form of a refactoring effort. One of the ways of measuring architectural changes in large codebases that can lead to technical debt is by looking at pertinent quality attributes, primary of which, in my opinion, is maintainability. Maintainability is ambiguous though and can cover a wide spectrum of things. What exactly do we mean by it? Let us codify it using a set of concrete metrics. In this case, I have chosen the following metrics:
2.1 LOC
LOC measures the number of executable lines of code in each release, ignoring comments and blank lines, and is widely used as a baseline measure of quality [1][2]. A system with more LOC is typically more difficult to maintain. LOC and defect density have an inverse relationship [3][4][5], or according to some studies a curvilinear relationship [6]. This may seem counterintuitive at first. The explanation is that firstly, architecture does not change at the same rate as LOC, and secondly, that a sizable number of defects occur within the interfaces that tie modules or components together. In a small system, the likelihood of a defect occurring in an interface is fairly high. As the system's size increases, most of the new code ends up going into modules and components rather than into new interfaces, and hence the propensity for defects per LOC goes down as LOC goes up.
Here, the set of analyzed files includes all files that meet our file-type filter1 excluding unit tests. The original version of this article included unit tests in the analysis since the initial aim was to show the evolution of the Firefox codebase. Now, with the focus shifted to comparing Firefox to other codebases, which will be the subject of an upcoming article, it no longer makes sense to have those files as part of the analysis, even with their negligible impact on the results.
1 .c, .C, .cc, .cpp, .css, .cxx, .h, .H, .hh, .hpp, .htm, .html, .hxx, .inl, .java, .js, .jsm, .py, .s, .xml
2.2 Cyclomatic complexity
Cyclomatic complexity, developed by Thomas McCabe in 1976, measures the number of linearly independent paths within a software system and can be applied either to the entire system or to a constituent part [7]. By viewing a block of code as a control graph, the nodes constitute indivisible lines of code that execute in sequence and the directed edges connect two nodes if one can occur after the other. So, for example, branching constructs like if-else statements would result in a node being connected to two output nodes, one for each branch.
Cyclomatic complexity is defined as v(G) = e – n + 2p where v(G) is the cyclomatic number of a graph G, e is the number of edges, n is the number of nodes and p is the number of connected components, or exit nodes, in the graph. A block of code with a single set of if-else statements would be calculated as follows: e = 6, n = 6 and p = 1, therefore, v(G) = 6 – 6 + 2 * 1 = 2. The additive nature of the metric means that the complexity of several graphs is equal to the sum of each graph. In our measure of cyclomatic complexity, we control for size and hence, the value for each release is per 1,000 LOC.
2.3 First-order density
First-order density measures the number of direct dependencies between files. It is calculated by first building an adjacency matrix, sometimes called a Design Structure Matrix (DSM), using the set of source-code files sorted by their hierarchical directory structure. Wherever a file in a particular row depends on a file in a particular column, we mark the element with a '1'. Because we are only capturing direct dependencies, this matrix is referred to as a first-order dependency matrix. The density of said matrix is the first-order density. For releases, we show it per 10,000 file pairs whereas for modules, where matrices are generally not as sparse, we show the density as a percentage.
In such a matrix, a square-shaped cluster indicates many dependencies between files within a module. All the dots to the right and left of a cluster are files that the module depends on. All files above and below it are files that depend on it. In many paradigms, modularity (low coupling, high cohesion) is a desirable quality attribute. Hence, an ideal system has modules that have more intra-module dependencies and fewer inter-module dependencies.
2.4 Propagation cost
Propagation cost measures direct as well as indirect dependencies between files in a codebase. In practical terms, it gives a sense of the proportion of files that may be impacted, on average, when a change is made to a randomly chosen file [8][9].
The process of transforming a first-order dependency matrix that captures only direct dependencies between files to a visibility matrix, also known as a reachability matrix, that captures indirect dependencies as well is achieved through matrix multiplication by raising the first-order dependency matrix to multiple successive powers until we achieve its transitive closure. Thus, a matrix raised to the power of two would show the indirect dependencies between elements that have a path length of two, i.e. calls from A to C, if A calls B and B calls C. Thereafter, by summing these matrices together one gets the visibility matrix.
For this ripple effect to be of use in analysis, the density of the visibility matrix is captured within the metric that we call propagation cost.
2.5 Core size
Core files are files that are highly interconnected via a chain of cyclic dependencies and have been shown in various studies to have a higher propensity for defects [10]. They are one of four types of files that one sees when plotting files along the axes of fan-in and fan-out2, the intuition for this breakout being that different directions and magnitudes of dependencies have varying impacts on software quality. This intuition has been validated by several studies [11][12] and a smaller core has been shown to result in fewer defects.
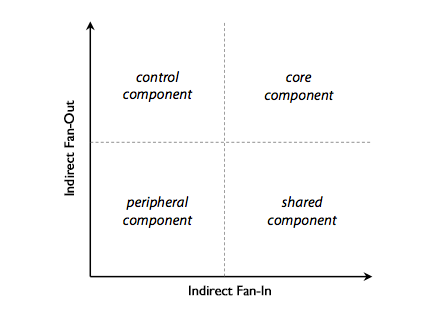
Diagram 1: Four types of files.
Other types of files are peripheral files, which don’t depend on a lot of files and don't have a lot of files depend on them; shared files, which don’t depend on a lot of files, but have a lot of files depend on them and control files, which depend on a lot of files, but don’t have a lot of files depend on them.
Core size is the percentage of files with one or more dependencies that have a high fan-in and a high fan-out. The fan-in and fan-out values for files are taken from the visibility matrix rather than the first-order matrix, and are hence referred to as indirect fan-in and indirect fan-out. Here, by looking at the distribution of files' indirect fan-in and fan-out values, it becomes apparent that neither is smooth, but rather exhibits at least one clear discontinuity point, as shown in Chart 1 below.
Since it makes practical sense to think of files beyond such a point as being part of a large cycle of calls, we use this point to calculate the core. A core file is therefore one whose indirect fan-in is greater than the first discontinuity point in the distribution of fan-in values and whose indirect fan-out is greater than the first discontinuity point in the distribution of fan-out values3.
2 Fan-in captures the count of dependencies flowing into an element; fan-out captures the count of dependencies flowing out of an element.
3 The spreadsheet referenced below includes two columns for core size; one calculated as described and one calculated using medians. When medians are used, we see a series of higher core sizes (mean=40%); both series are highly and positively correlated.
3 Method
3.1 Data
The dataset consists of the codebases of 23 major releases of Firefox, from v1.0 to v20.0, all of which are large enough for analysis and so we don't have to worry about adversely impacting our architectural measures as a result of having too few files. Said measures can become unreliable when codebases are too small, which makes intuitive sense. Furthermore, it is not very meaningful to talk about dependencies when the system size is small enough for one person to be knowledgeable about all of its modules. The following table shows some descriptive statistics for the 23 codebases.
| Mean | Median | Stdev | Min | Max | |
| loc | 2,885,799 | 2,686,348 | 595,408 | 2,066,655 | 4,012,434 |
| cyclomatic complexity | 188.37 | 187.54 | 18.52 | 155.67 | 217.95 |
| first-order density | 7.82 | 8.43 | 1.64 | 5.17 | 10.64 |
| propagation cost | 17.45% | 19.18% | 5.93% | 4.02% | 24.24% |
| core size | 21.39% | 22.73% | 6.17% | 6.84% | 28.84% |
| files | 13,266 | 11,907 | 2,844 | 9,478 | 18,460 |
Table 1: Descriptive statistics for the set of Firefox releases (n=23)
Full details are available in the spreadsheet here and the .json file here.
For each of the past five releases of Firefox (v16.0 to v20.0), we also analyze individual modules. A module is defined as a top-level directory in the codebase that is also listed on the Mozilla Source Code Directory Structure page. Modules that have fewer than several hundreds of files are not analyzed for the reasons mentioned earlier. The following table shows descriptive statistics for our set of modules. Comparing, say, the mean core size in both tables suggests that some portion of that measure for Firefox releases is driven by some of the smaller modules.
| Mean | Median | Stdev | Min | Max | |
| loc | 314,765 | 293,705 | 193,555 | 53,935 | 720,382 |
| cyclomatic complexity | 158.97 | 157.19 | 26.05 | 80.72 | 207.29 |
| first-order density | 0.44% | 0.38% | 0.33% | 0.05% | 1.35% |
| propagation cost | 8.58% | 6.16% | 7.13% | 1.00% | 25.04% |
| core size | 7.22% | 5.73% | 7.28% | 0% | 32.55% |
| files | 2,306 | 1,970 | 1,825 | 448 | 6,806 |
Table 2: Descriptive statistics for the set of Firefox modules (n=70)
Full details are available in the spreadsheet here and the .json file here.
Modules are a bit more nuanced since we generally want most of the interaction between files to happen within modules rather than between them. For simplicity, we consider a module to be a system, which allows us to continue using the same measures of goodness discussed earlier. Hence, a module that has a higher density of dependencies is considered to be less maintainable than one with a lower density. This only gives partial insight into a module's architecture, and begs the question: Well, how do the number and density of internal calls compare with the number and density of external ones? That question is part of the motivation for the third, currently in-progress, view on the Evolution of the Firefox Codebase page.
The distribution of files' fan-in and fan-out values shows two distinct patterns, both of which are skewed. For direct fan-in and fan-out, we see a smooth distribution with a very long tail indicating that the majority of files don't have that many direct inward and outward calls. For indirect fan-in and fan-out values, which as mentioned earlier, are used to classify a file into one of several types and consequently calculate the core size for a codebase for module, we see that files either don't have that many indirect calls or are part of a cluster of files that has a high number of calls. Almost all sets of files that were analyzed exhibit this “Nessie”-like pattern.
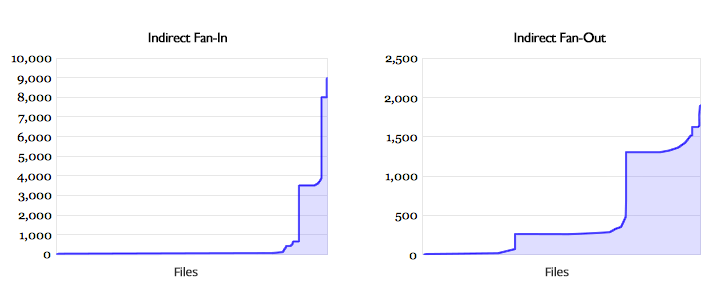
Chart 1: Distribution of indirect fan-in and fan-out for the 12,822 files in Firefox v1.0.
3.2 Processing the data
Processing the data involves the use of a set of tools and scripts. The general workflow is shown in the following diagram.
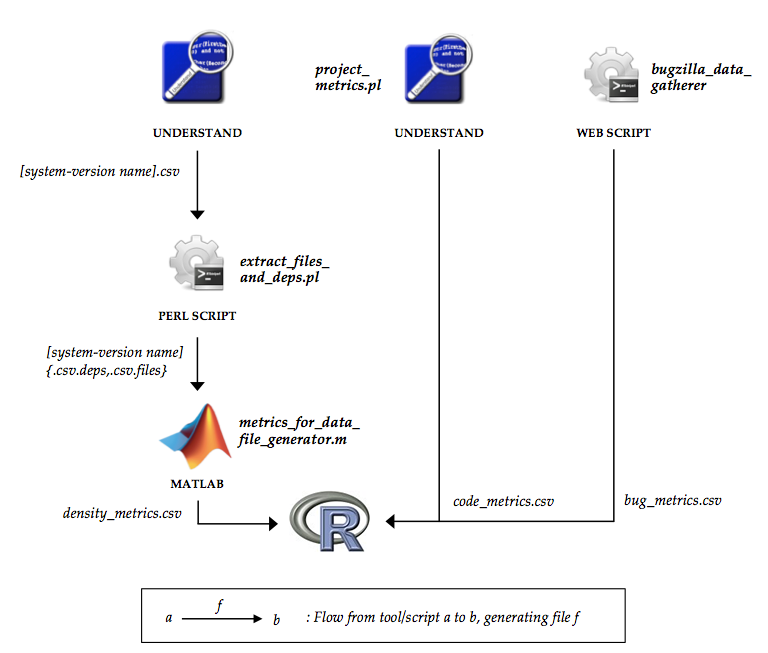
Diagram 2: Processing the data.
The tool set is comprised of a static analysis tool called Understand, MATLAB and a number of local and Web scripts. The input to the static analysis tool is a particular Firefox release's codebase or a particular module's code. The end-result is a set of metrics that are consolidated into a single dataset that may be analyzed further by a statistical analysis tool. The three data sources that form the final dataset are enumerated below.
3.2.1 Common complexity metrics
The static analysis tool outputs common metrics such as LOC and cyclomatic complexity, which can be extracted either through a user interface or via a Perl API. Generating these and similarly common metrics for each codebase can be time-consuming. Furthermore, it seems like the tool has to reprocess files every time a project is reopened. On the plus side, we get a large amount of useful data that can be broken down by system, module or component.
3.2.2 Dependency metrics
The static analysis tool is used to export dependency data for a particular release. The generated .csv file has three columns: from, to and references. The first two columns store the full path of each file and the third is the number of references between the two files. Each row in the file is a source-code file pair. The .csv file is then processed by a Perl script, which replaces the data in the first two columns with integers that reference file names stored in a separate lookup file. That processed data is then used as input for a MATLAB script, which uses it to a) build a first-order dependency matrix, b) raise it to multiple powers until its transitive closure is reached resulting in a visibility matrix and c) generate the desired complexity measures – first-order density, propagation cost, core size and a few others.
Here is an example of a first-order matrix of files in the gfx module in Firefox 20 (left) and the visibility matrix for the same module (right). Notice how new patterns of dependencies emerge when we start considering indirect dependencies.
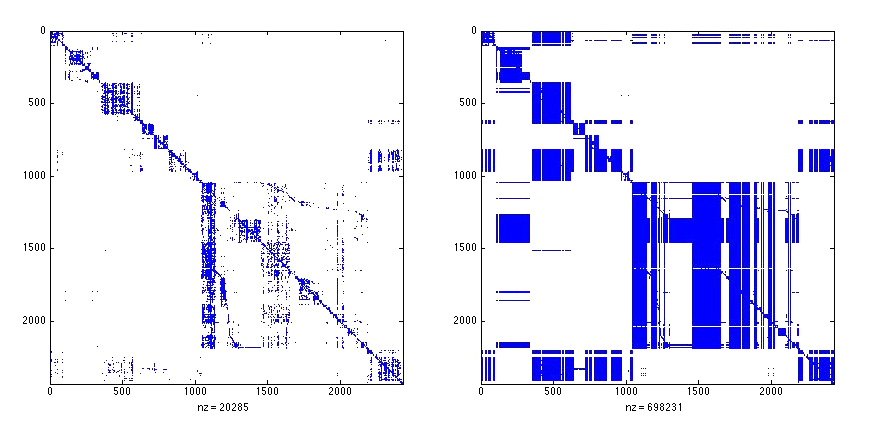
Diagram 3: A first-order dependency matrix (left) and visibility matrix (right) for the same module.
3.2.3 Defect metrics
We use a Web script to query the Bugzilla database and gather defect data for individual releases. The parameters of our request use the following criteria:
- Status ≠ “unconfirmed”
- Resolution = “fixed” or resolution = “---”4
- Severity ≠ “enhancement”
- Product = “Firefox”
- Version = the set of major releases up to v20.0
One of the wrinkles with Firefox's defect activity data is that defects aren't always mapped to the versions in which they were discovered. We are currently not doing much with the defect data, mostly because we have too few observations to do any meaningful statistical analysis with them. A reasonably robust method used in the past for accommodating unassigned defects involved defining them as follows:
An unassigned defect d is caused by version v of a system if it was created within time period t to t’, where t is the release date of v and t' is the release date of the next version. Per the conditions used in the search query shown above, the unassigned defect d must not have a status of unconfirmed or a resolution value other than fixed.
Though defects created by users within a particular time period need not necessarily map to the previous release, the assumption is that the second criterion would filter out most of those cases, i.e. a defect discovered by a user in an older version will likely have been resolved in the latest version. In previous work, this method was used to calculate assigned defects for a set of system-versions and got results that were very close to the actual number of defects reported by Bugzilla for those system-versions, with the average overlap being 80% [12].
4 The resolution field can be either ‘fixed’ or ‘---’, which accommodates both sets of closed and fixed defects as well as confirmed open ones.
4 Findings
4.1 Architectural indicators generally show satisfactory levels of maintainability
Cyclomatic complexity shows a slow decreasing trend at a mean rate of -1.11% with the most recent release showing it to be the lowest ever. This is a good thing. It indicates that the code within files is, on average, getting less complex.
Chart 2: Cyclomatic complexity.
LOC code is growing at a mean rate of 3.07%. Using other open-source codebases as benchmarks, this appears to be a reasonable rate. Only in v4.0 did LOC grow at a noticeably larger rate of 18.53%. Given the context, this may be understandable seeing how significant a release v4.0 was for Mozilla. At no point do we see substantial drops in LOC, something that would be indicative of a major refactoring effort, as was the case with the original Mozilla browser.
Chart 3: LOC.
We see a decreasing trend in first-order density, with the most significant drop occurring in v4.0 (-14.92%). We see a general increase in direct dependencies in the subset of releases surrounding v3.0, some of which were in development for long periods of time. The largest growth is 19.85% and occurrs in v3.0. The mean number of dependencies per 10,000 file pairs is 7.82, with the maximum being 10.64 in v3.5 and the minimum being 5.17 in the v18.0. This tells us that the complexity between files as measured by direct dependencies has decreased, which is a good thing. For the average Firefox release, changing a randomly chosen file has the potential of impacting 0.000782% of files, or ten files.
Chart 4: First-order density.
We see a growing propagation cost that starts at 4% and continues to increase with a mean of 58.86% up until v5.0, after which it stabilizes, seeing as its growth goes down to 2.09%. v5.0 is an interesting release as it is the first in Mozilla's Rapid Release Cycle. The shift in propagation cost in v3.5 may be considered a regime shift. In practical terms, what propagation cost shows is that a change to a randomly selected file in Firefox has the potential to ultimately impact 17.45% of files. For the average Firefox release that means around 2,308 files. The stability of propagation cost is a good indicator, and the value is in my experience reasonable. Propagation cost varies between 4.02% in v1.0 and 24.24% in v5.0.
Chart 5: Propagation cost.
Core size, similarly, shows a regime shift in v3.5 with the mean size increasing from 9.93% to 23.80%. v3.5 follows v3.0, which is the only Firefox release to have been in development for two years. All others before the Rapid Release Cycle spent approximately one year in development. Further investigation would be needed to uncover what during those years of development may have been the driver of this uplift in the number of highly interconnected files. Note that the total number of dependencies also went up in that release, following which it begins its slow downward trend. As with propagation cost, we see core size stabilizing after v5.0.
Chart 6: Core size.
4.2 Switching to the rapid release cycle (RRC) has had a positive impact on maintainability
RRC began with v5.0 of Firefox and aimed to constrain the release cycle to 6-week time periods and tighten the software development lifecycle. Comparing the seven observations from before the switch to RRC with the 16 afterwards reveals the following results.
Propagation cost has clearly gone up, despite RRC, however, looking at its mean release-over-release growth, it becomes evident that it has become much less volatile, having gone down from 58.86% to just 2.09%, which is a good improvement. Its standard deviation has dropped from 105.26% to 14.49%.
Core size is, similarly, much less volatile after RRC, with its mean growth dropping from 35.47% to 2.73% and its standard deviation from 88.08% to 16.24%.
LOC's growth saw a substantial decrease following RRC with its mean growth dropping from 4.02% to 2.69%, which means that we now add an average of 77.63K lines of code per release compared to 116.01K lines of code before. This is to be expected given the much shorter development periods and is in fact one of the reasons that drives organizations to adopt shorter and more nimble development lifecycles.
First-order density has improved seeing as the mean density has gone down from 9.29 to 7.17, though that seems to be despite the switch to RRC rather than because of it; first-order density appears to have in fact exhibited a downward trend from v3.5 onwards. The biggest dip occurred in v4.0 where it dropped 14.92%.
Cyclomatic complexity has been steadily improving over time, though like density, the trend of improvement started before the switch to RRC. Having said that, its mean growth following the switch is a slightly better -1.26% compared to -0.71% before.
4.3 A subset of modules appears to be noticeably more complex than the rest
Splitting our module-level data by module and looking at the mean values for each module for each of the above metrics gives some insight into how the different modules fare in terms of complexity, as shown in the following charts.
In terms of internal complexity, our modules range from a mean cyclomatic complexity of 121.43 to 194.48.
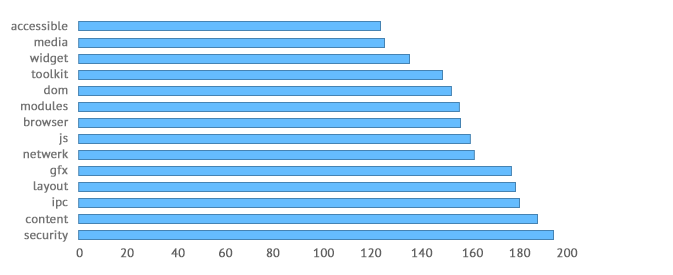
Chart 7: Mean cyclomatic complexity.
Looking at first-order density, browser stands out as having a mean density that is noticeably higher than the next module, that is, 1.24% compared to 0.73%.
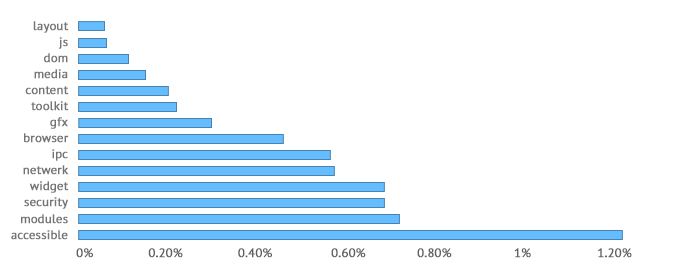
Chart 8: Mean first-order density.
With propagation cost, we see that the three modules with the highest mean propagation costs, accessible, security and browser, are all noticeably higher than the remaining modules, being as they are 21.32%, 20.85% and 19.98%, respectively. In some releases, such as in v18, we see the propagation cost of gfx jump from 8.93% to 16.44%, indicating a possibly adverse architectural change that was made in that release. The measure comes down in future releases for that module.
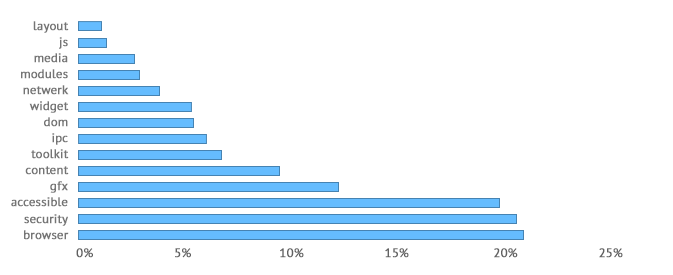
Chart 9: Mean propagation cost.
With core size, we see that the module with the highest mean core size, security, is noticeably higher than the remaining modules, being as it is 25.91%. Some modules have tiny cores, and at least one module, media, has no discernible core.
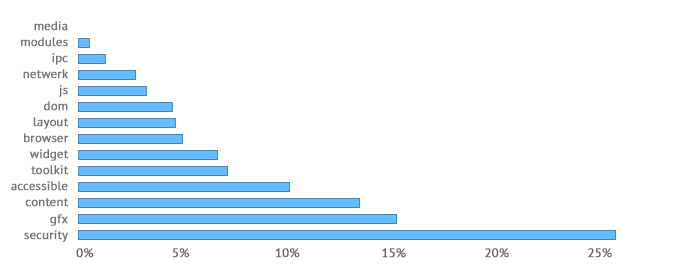
Chart 10: Mean core size.
5 Take-away
It is impressive that an open-source project developed and maintained by a distributed team of paid staff and volunteers has been able to produce a product as impactful as the Firefox browser. One sees larger, more expensive, software projects become drastically less maintainable in only a few years by virtue of their development processes becoming more chaotic and coding best practices being abandoned in favor of premature pragmatism. With Firefox, We see the decision to move to a tighter, more predictable, development process possibly helping to improve quality.
Firefox's core size may be somewhat elevated indicating that highly interconnected files make up a sizable portion of the codebase. Though the measure shows no signs of following an upward trend, that may quickly change should, say, any organizational dynamics change. The changes in version 3.5 of the product that led to Firefox's core size increasing by over 200% may be worth looking into. Having said that, the analysis reveals no imminently alarming red flags when it comes to maintainability. A number of modules, such as accessible and security, frequently appear among the most complex modules. Further investigation may be helpful in identifying why that is the case.
A caveat worth mentioning in closing is that, as with any set of software metrics, the measures described herein only reveal part of the picture. The chosen architectural measures make the assumption that directory structure reflects the logical hierarchy of modules within Firefox. I have not looked into the extent to which this is the case.
6 Next steps
An upcoming article will focus on defects, specifically, classes that show the highest propensity for regressions. It will also take a closer look at how Firefox's architectural measures of complexity compare to those of other open-source projects.
7 Acknowledgements
Thanks to Brendan Eich, Brendan Colloran and Saptarshi Guha for their feedback, which helped improve this writeup. Thanks to Alan MacCormack for sharing his experience with working with several of the measures that were discussed here and Gilbert FitzGerald and André Klapper for helping with some of the exploratory work that led up to this project.
8 References
[1] Hatton, L. "The role of empiricism in improving the reliability of future software." Keynote, 2008. http://www.leshatton.org.
[2] Shore, J. "An Approximate Measure of Technical Debt." November 19, 2008. http://jamesshore.com/Blog/An-Approximate-Measure-of-Technical-Debt.html (accessed February 2, 2013).
[3] Kan, S. H. Metrics and Models in Software Quality Engineering. Addison Wesley, 1995.
[4] Basili, V. R., and B. T. Perricone. "Software Errors and Complexity: An Empirical Investigation." Communications of the ACM, January 1984, pp. 42-52.
[5] Shen, V., T. Yu, S. Thebaut and L. Paulsen. "Identifying Error-Prone Software - an Empirical Study." IEEE Transactions on Software Engineering, Vol. SE-11, No. 4, April 1985, pp. 317-324.
[6] Withrow, C. "Error Density and Size in Ada Software." IEEE Software, 1990.
[7] McCabe, T. J. "A Complexity Measure." IEEE Transactions on Software Engineering 2, no. 4 (December 1976): 308-320.
[8] MacCormack, A., J. Rusnak, and C. Baldwin. "Exploring the Structure of Complex Software Designs: An Empirical Study of Open Source and Proprietary Code." Institute for Operations Research and the Management Sciences (INFORMS) 52, no. 7, 2006.
[9] Eppinger, S. D. and T. R. Browning. Design Structure Matrix Methods and Applications. MIT Press, 2012.
[10] MacCormack, A., and D. Sturtevant. "System Design and the Cost of Complexity: Putting a Value on Modularity." AoM 71st Annual Meeting, 2011.
[11] MacCormack, A., C. Baldwin, and J. Rusnak. "The Architecture of Complex Systems: Do Core-periphery Structures Dominate?" MIT Research Paper no. 4770-10, Harvard Business School Finance Working Paper no. 1539115, 2010.
[12] Almossawi, A., "An Empirical Study of Defects and Reopened Defects in GNOME." Unpublished, 2012.
Don't forget to check out the Evolution of the Firefox Codebase page, which allows you to interactively explore the data described herein. This work is being shared under a Creative Commons license (CC BY-NC). To share your thoughts, feel free to chat with me on Twitter. Once again, you may download the data from here and here.
ali@mozilla.com · May 15, 2013 · Updated on May 24, 2013 to include .jsm files and on July 26, 2013 to take out unit tests. Thanks to Fabrice Desré, Dietrich Ayala and Dave Townsend for notifying me of the former.