What Does the Fox Weigh? ♫
Unlike physical objects, it might not always be apparent what wear and tear looks like in software. Parts don’t squeak or crack or moan in the same way, and to the chagrin of many a researcher, there are no fundamental laws in software like there are in nature. And so best practices and good advice are generally the camels on whose backs we travel, occasionally sneering at onlookers for lacking the requisite level of faith in our idealized theories of how things ought to be done.
Yet the road to engineering from mere development, a characterization that I first read in Garlan and Shaw’s introduction to software architecture, is filled with noble efforts like that of devising metrics and building models of quality to help track and manage the complexity that is inherent in software. Complexity that is essential, as Brooks might say.
But quality is ambiguous. Nobody really knows what one thing it is meant to measure, which is why we define quality in concrete and local terms. “Building for quality means building for maintainability,” one may proclaim, to which another may respond, “To us, it’s more about performance.” Often though, it is a combination of attributes that span multiple categories.
Maintainability is what I’m interested in, for personal reasons, as I have witnessed the wrath of code that rips through muscle and bone and condemns the souls of all who dare approach it to eternal damnation—technical debt as it is sometimes called. The metaphor is a useful one, since it posits that software development malpractices incur a debt that must be paid at some point in the future in the form of time, effort or defects.
This accumulation of debt can take months to become noticeable and so detecting it is only possible when we observe a system over a period of time. It is by way of this sort of transparency that we see things like drops and rises in a system’s level of maintainability, indicators that we can then use to inform decisions about the product, process and project.
In order to provide such a lens for those interested in tracking the maintainability of the Firefox codebase, I have put together a dashboard that tracks six measures of architectural complexity. They constitute a set of measures that studies have shown to be good predictors of quality. Many other measures exist too.
Size
1. Lines of code: The number of executable lines of code, not counting comments and blank lines. Though lines of code is the simplest measure of a system’s complexity, some practitioners argue that it remains one of the best predictors of quality.
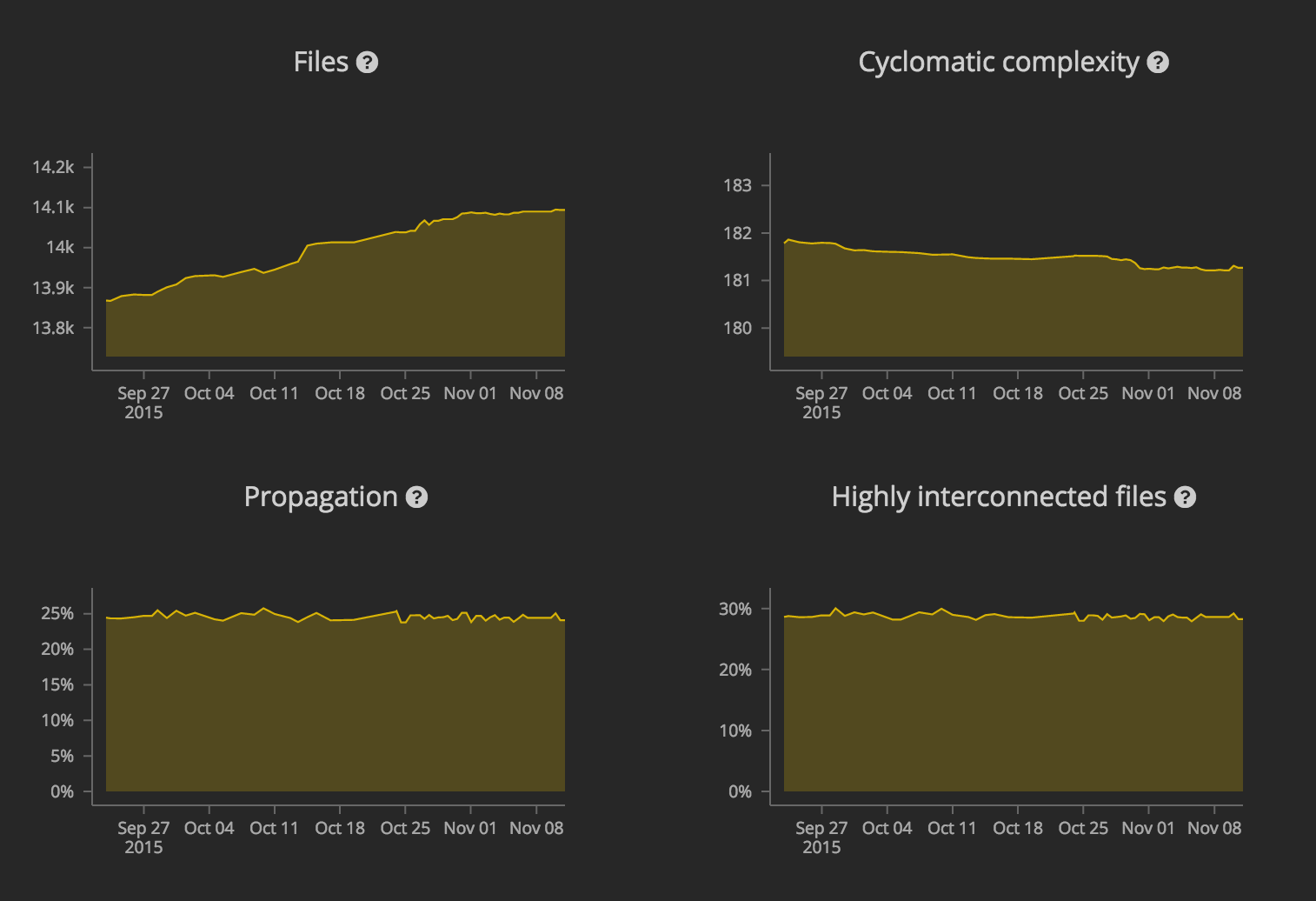
2. Files: The number of files, not counting filtered files and unit tests. A file is analogous to a component in other engineered systems, seeing as it is not as atomic as, say, a screw or a bolt and not as large as a module.
Intra-component complexity
3. Cyclomatic complexity: The number of linearly independent paths of execution within a system per line of code. These are paths that occur as a result of branching constructs like if-else statements. For the sake of readability, the measure is per 1,000 lines of code, so a cyclomatic complexity value of 200 means that there are around 200 independent paths in every 1,000 lines of code.
Inter-component complexity
4. Dependencies: The number of files that the average file can directly impact. A file depends on another if it includes, calls, sets, uses, casts, or refers to one or more items in that file. We can determine the average number of dependencies in a system by building an adjacency matrix of its components.
5. Propagation: The proportion of files in a system that are connected, either directly or indirectly. In practical terms, propagation gives a sense of the total reach of a change to a file. We calculate propagation through a process of matrix multiplication.
6. Highly interconnected files: Files that are interconnected via a chain of cyclic dependencies. These are pairs of files in a system that have a lot of dependencies between each other. Highly interconnected files may be correlated with propagation.
* * *
The analysis runs daily on revisions in Mozilla’s central tree, first on the entire codebase and then on a set of top-level directories, which are meant to constitute individual modules. In addition to the interface, the dashboard includes an endpoint that allows one to specify the path to a file in the Firefox codebase, for which it returns the set of inward and outward dependencies. This information can be useful for things like determining what subset of tests to run for a particular commit.
The entire code for the analyzer and the interface, most of which is Python and JavaScript, is available in a public repository, as is the documentation for how to set things up and modify default behavior.
By following the documentation, you should be able to run the analysis on your own codebases. A previous project, for instance, ran it on 23 releases of Chromium, which served as a useful benchmark. Other areas of focus may include identifying refactoring patterns and looking into possible relationships between frequency of change to LOC and files and regressions. Furthermore, comparing metrics across modules might be valuable in providing insight into various team dynamics.
Seeing as the work is still at a fairly embryonic stage, if you’re interested in this sort of thing, I invite you to get in touch or contribute your thoughts on GitHub.